Here is a fun story from a few years ago.
My spouse is a paleontologist (Figure 1).

But Sara doesn’t work on, like, T. rex—they work on microfossils, in particular these tiny, sand-grained-sized amoebas called foraminifera, which form shells that fossilize.1 (You can read about my spouse’s work here, if you’re interested! Yes, they are a lot cooler than me.) Foraminifera (or “forams” for short) are really useful because 1) they’re everywhere, so you just have to kind of scoop up some ocean dirt and you can find a lot of them and 2) their various characteristics like shape and shell chemistry can help inform how old a rock layer is, and what the conditions were like in the ocean when it formed. Perhaps unsurprisingly, those characteristics are also of great interest to oil companies, in their endless search for oil deposits to exploit (and they were even more so in the era before radiometric dating became commonplace).
Our story starts in the second half of the 20th century, when the oil company Arco hired some paleontologists to… dig around, I guess, as paleontologists do. Specifically their goal was to use forams to figure out where Arco should drill for oil.

Always interested in increasing the efficiency with which they were destroying our planet, in the ’80s Arco started digitally recording the data they were collecting, using the early “microcomputers” that were becoming widespread at that time. Via some chain of events that I don’t entirely understand, floppy disks containing that data ended up in the University of California Museum of Paleontology (UCMP), home of Osborne the T. rex, and where my spouse was working on their PhD in 2018. And there were a LOT of floppies (Figure 3)—containing a total of 2.5 million records, or so.

Such a large dataset seemed ripe with potential for doing cool paleontology studies without even having to go outside,2 so my spouse got their hands on a floppy disk drive, checked out the data, and… it looked like this:
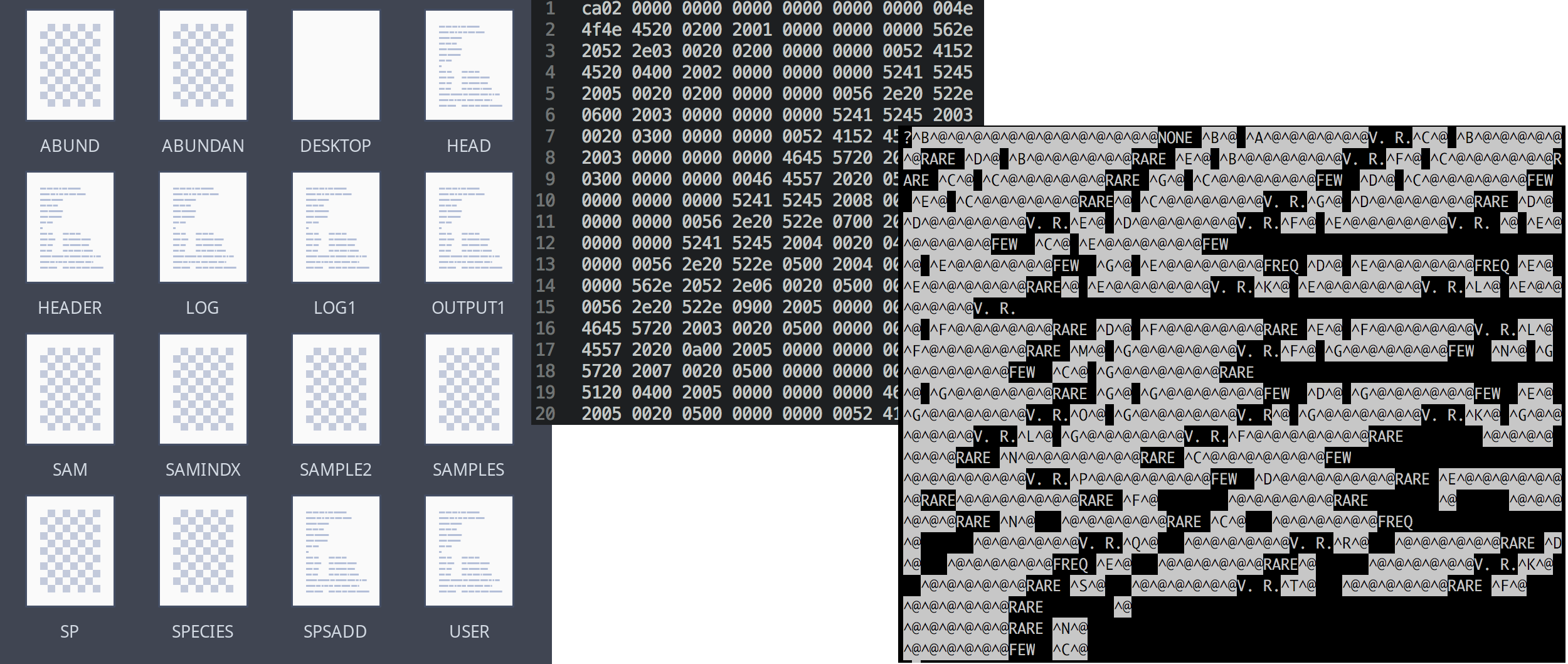
It was all in some weird, mysterious format (rather reminiscent of the terminals in Fallout!). From some discussion with the director of the UCMP who accepted the floppies, Sara found out that the data had been recorded via a proprietary program called BUGIN,3 written in the 80s in FORTRAN for MS-DOS. The director reached out to a contact who was formerly an ARCO employee about converting the files, and the former employee responded that they knew how to do it, but it would cost… twenty thousand dollars.

$20,000??? To run an already-existing piece of software against some data? I guess I shouldn’t be surprised considering the general behavior of oil companies and their employees, but WOW. Even worse, it sounded like the museum was seriously considering going through with it—millions of already-collected paleontological records were simply too good to pass up.
If anything gets me worked up, it’s stuff like this. Holding valuable research data hostage in order to price gouge a publicly funded university is like, the definition of depravity. (Also, I’m not sure if this same “former ARCO employee” is the one who “gifted” UCMP the floppies in the first place, but if so, that would be truly legendary levels of exploitative behavior).
I decided to take a look around the web and see if I could find any existing tools for decoding BUGIN data. Unsurprisingly, I just found one hit, a company run by a former ARCO employee, selling a “service” converting BUGIN files to CSV, as well as other paleontology software (Figure 5).

I poked around their website a bit, and honestly, I can only be impressed at their audacity in selling software. Take for example a program they offer called “Merge Spreadsheets 2,” which can be yours for the low price of $75. What does “Merge Spreadsheets 2” do, you ask? It takes two CSV files, and, you guessed it, merges them into one CSV file. This task is also accomplished by the following single line of code on the Linux command line:4
paste -d ',' sheet1.csv sheet2.csv > merged.csvTruly groundbreaking engineering happening over at PAZ software. (Also, I am now extremely curious what technological innovations went into “Merge Spreadsheets 2” compared to what was presumably the original “Merge Spreadsheets”?)
Anyway, this situation was the perfect nerd snipe: an interesting retro computer problem paired with a little bit of preventing exploitative capitalism? Sorry to the Floquet time crystals I was supposed to be working on, it would have to wait. Time to put on a hoodie, find a dark room somewhere, turn on synthwave, and hack.
Exploring the files
Let’s take a look at the bytes in one of the files for a moment (click to enlarge):
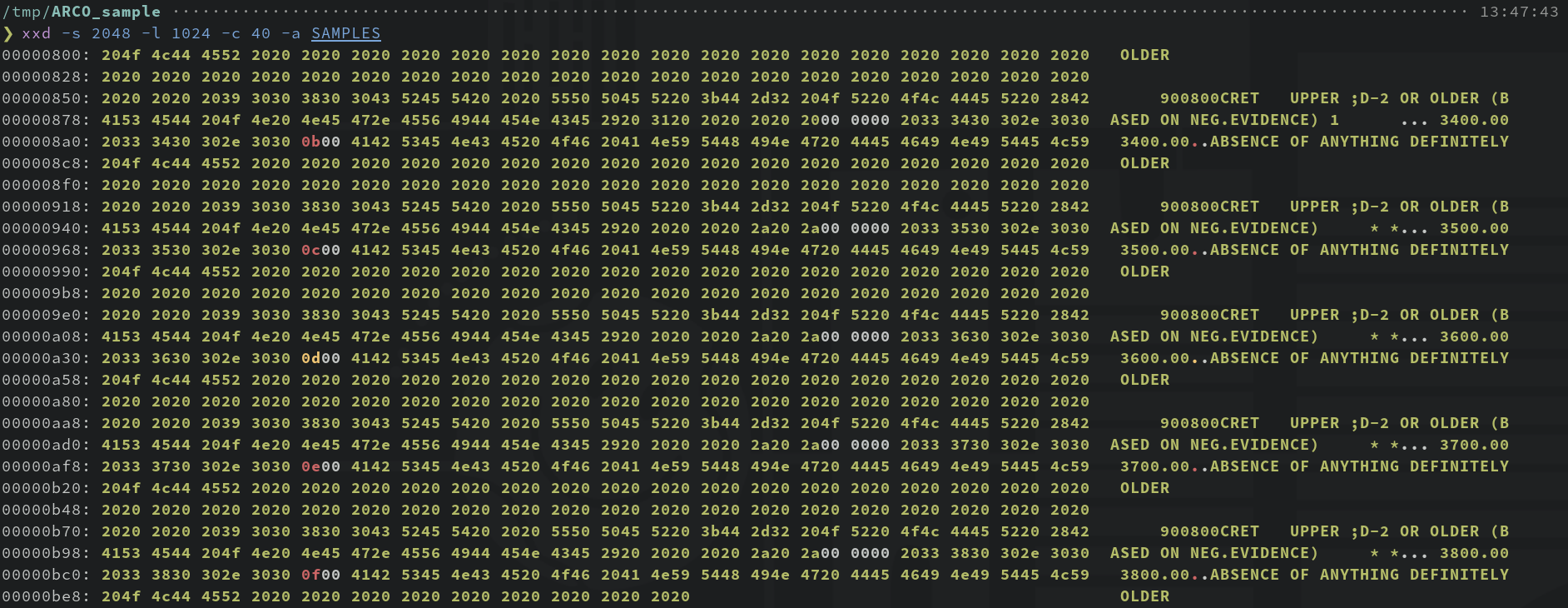
First of all, we see some ASCII—that’s promising! There is also some other stuff, which is a bit unfortunate, but we can at least tell that the file seems to contain the rows of a table, concatenated one after another. Helpfully, it appears that each row is exactly 200 bytes. Furthermore it seems that each row consists of a series of data fields. My guess was that each data field gets a certain number of bytes, and the ones that don’t seem to be ASCII probably correspond to numerical values stored in binary, either in integer or floating point format.
I spent a few days trying to figure out the data types and byte lengths of each of these fields by hand, and it felt like I was getting close, but certain things just didn’t make sense. For example, there was one field that just contained seemingly arbitrary numbers, like 30332053, no matter how I parsed it. Worse, it was totally unclear what each field corresponded to. Was 80 the last two digits of the year the sample was collected? Or was it the sample depth in meters? Or was it a sample ID number? Even with reasonably solid guesses, the scientific integrity of using this data without more confidence in what it represented felt suspect.
Sara with a clutch find
Then a very exciting breakthrough happened. Sara was digging around (stereotypical, lol) in the paleontology museum and found a binder labeled BUGIN MANUAL containing a bunch of type-written pages. At the end were several pages containing lines like this:
(F8.2,F8.2,I2,A40,A4,A25,A5,A5,A4,A32,A6,A6,A44,A8)This is a FORTRAN data formatting string. Each element of the list describes a data type (“F” for float, “I” for integer, “A” for ASCII text), and an integer representing the number of bytes to be used for that value. (The extra .2 on the floats indicates the desired precision). Note that the total number of bytes is 197, which corresponds nicely to the 200 bytes per row we found earlier (presumably the byte count is being padded out to the next multiple of 4 or 8). Even better, the pages also contained the column headers corresponding to each field, describing what information was stored in them!
Unfortunately, it quickly became clear that the binder was full of typos. (What a roller coaster we were on). But it was accurate enough to give me a big leg up, and with some fiddling I was able to nail down the correct values with confidence.
Putting it all together
The final step was to figure out how the data in each of the files (e.g. SPECIES, ABUNDAN, etc.) related to each other; in the interest of keeping this blog post to a reasonable length, I’ll skip the details, and just say: it was reasonably straightforward to reverse engineer. With that, I had everything I needed to write a Python script, which I called BUGOUT, that parses BUGIN data and outputs it to a useable format.
Or, like, usable-ish. Given the strong Fallout vibes of this whole project, I couldn’t help but have a little fun with it.
Sara brought this to their advisor, who said: “Wow I am so thankful to Greg. But… um… is it possible to change the interface to something easier to use?”
lol. oops. Probably should have told them that there is a command line switch to output the data to CSV instead.
In case anyone else ends up with old data that had been recorded in BUGIN, I put BUGOUT on GitHub here. Maybe someone will find it useful.
Snacks
A few weeks later Sara told me that their department was having a catered happy hour, and that I should come. I went up to get food, and one of the senior professors cleared his throat and said, “I don’t think I know you. Are you part of this department? This event is for people who work in the museum.”
“Oh, sorry, um. I’m Sara’s husband. They said it was OK if I came to get some snacks?”
His eyes got wide and he said, “Wait. Sara’s husband? The one who decoded the ARCO data? Oh my god, take as many snacks as you want! Take home a plate!”
The snacks were yummy, but nothing compared to the satisfaction of keeping thousands of dollars of grant money from going to some crappy company for no good reason, with the joy of digging through ancient computer data as an extra bonus. (Maybe we’re all a little bit paleontologists in our own way.)
P.S. if this post was fun for you, I highly recommend the video game TIS-100. Just, uh, don’t try it out when you have any pressing deadlines coming up. It might be hard to put down.
Footnotes
Actually a good fraction of the sand in the world is made up of forams!↩︎
Although as someone whose job never involves hiking mountains and going on boats, I don’t understand why anyone whose job could involve that would choose not to!↩︎
Apparently the oil people call forams “bugs,” really adding to the Fallout aesthetic.↩︎
OK, if we’re being totally fair, “Merge Spreadsheets 2” also deduplicates the columns, or something. But we don’t need to be fair, because the people who make this software certainly aren’t!↩︎